About system overload
Imagine a service that takes 100ms to handle a request and for some reason it is limited to picking a single request at a time. This means the system can cope with an average throughput of 10 requests per second. If for some reason the sustained average arrival rate increases, the system will be in a situation of overload and the only solution is to increase capacity, add more instances so we can handle more requests concurrently, or speed up process times, otherwise it will eventually fail. A good explanation of overload can be found on Wikipedia under Little’s law.
Overload is normally detected at higher level, when something goes down, or, if we have metrics, when we see high cpu usage, errors or slowness, but the root problem can lay and be tackled at different system levels, services, processes, thread pools.
What can we do then?
Scaling
The easiest scenario is when our system is able to be parallelized. Imagine the system as a pure function, every task that enters the system always has all the resources it needs to keep going forward. In this situation it can be considered an isolated unit and it should be relatively simple to assess its maximum throughput and just scale it horizontally (add more instances) when needed. Although this is a fairly easy case to solve, it is not common to have an all system that has this type of behavior. Normally, this system is a subcomponent of a wider system where units are grouped in a cluster, exposed through a common interface (load balancer), monitored and with automatic capacity adjustments, if using auto-scaling. However, this solution might lead to propagating the problem to downstream components and also it is not always feasible due to prohibitive costs.
In the other scenario we have a bottleneck in the system, a component that can not be parallelized or scaled, a point in which other components are dependent on to continue the data flow. In this situation, when load increases, in-flight tasks will be waiting for this resource to be available and the average time each task spends inside the system goes up, impacting throughput and probably degrading service’s responsiveness. When we hit some hard limit on our system there are two ways to avoid system failure
- drop - ignoring input instead of handling it
- back-pressure - resisting to input
Back-pressure
Back-pressure is a term that many software developers have already heard and probably dealt with at some point, but is seldom not clearly understood. Back-pressure comes from the mechanic of fluids world and is defined as
resistance or force opposing the desired flow of fluid through pipes, leading to friction loss and pressure drop.
A better definition for software is from the Reactive Manifesto
When one component is struggling to keep-up, the system as a whole needs to respond in a sensible way. It is unacceptable for the component under stress to fail catastrophically or to drop messages in an uncontrolled fashion. Since it can’t cope and it can’t fail it should communicate the fact that it is under stress to upstream components and so get them to reduce the load. This back-pressure is an important feedback mechanism that allows systems to gracefully respond to load rather than collapse under it. The back-pressure may cascade all the way up to the user, at which point responsiveness may degrade, but this mechanism will ensure that the system is resilient under load, and will provide information that may allow the system itself to apply other resources to help distribute the load, see Elasticity.
Simply put, back-pressure is a mechanism that allows a system to cope with overload by resisting to the given input, for example by blocking the caller while the request cannot be picked up. In this example we have multiple producers/callers that use a single worker to perform a task.
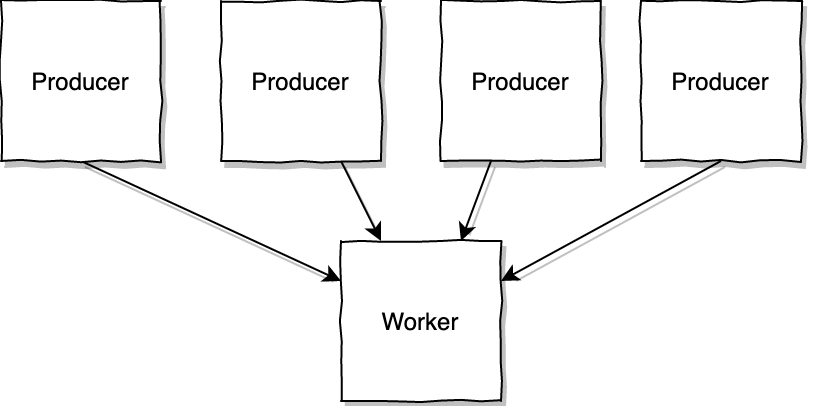
The callers are synchronous, they block waiting for the resource (the worker) to be available and handle their tasks. Similarly to a locking mechanism, this limits the number of tasks that are concurrently handled by the Worker, exerting back-pressure on the callers and avoiding overflow. This solves the problem, but at the cost of slow service and now we probably have clients complaining.
Buffering
A possible solution we can come up with is to add a queue between the Producers and the Worker.
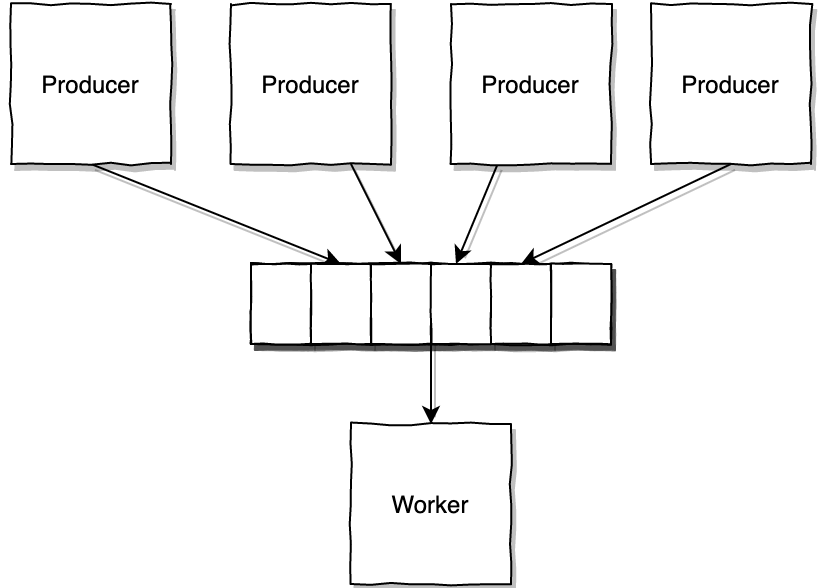
This queue makes the Producer->Worker communication asynchronous, which solves the problem for our Producers that are not blocking anymore and are now able to send tasks as fast as they can.
Although from the producers perspective it seems the system slowness is fixed, in reality, this is not helping us deal with the end-to-end latency or throughput, just postponing an eventual system failure. Adding a queue can be a good solution in some situations. If the system is subject to short load spikes for example, adding a queue can allow it to recover without losing data. However, this queue is one more possible point of failure that needs to be monitored and managed, so, before making this decision some questions need to be considered.
Are producers going to use this queue as a fire-and-forget mechanism? If so, how will we be able to propagate failures back? i.e. how will producers be aware of downstream failures so they can act on them? The queue will be keeping data for an arbitrary amount of time. What is going to happen to the queued tasks if for some reason there is a failure on the queue itself? And again, how will we let producers know that this failure occurred? We will need to put mechanisms in place so we can detect failures and communicate them back to users, otherwise we will end up breaking the end-to-end principle by retrying failed requests in intermediate components, or even completely obfuscating them from the callers (the ones with full request context), which can result in a less reliable system.
Also, depending on we solving these questions or not, we could lose the desireable property of back-pressure composability, we stop being able to connect two backpressuring components to form a larger system that also exerts back-pressure. We stop propagating back-pressure to the clients, pretending everything is working normally, while the downstream components can be overloaded.
Finally consider that if the queue is not bound in size it will be able to grow forever caped solely by the hard limits of the machine (RAM, disk), which means that if the load does not subside it will eventually lead to overflow and failure. On the other hand, if we limit the queue size we are back to the original dilemma, since, when we reach the queue limit we have to decide between
- block producers from pushing new tasks to the queue (back-pressure)
- drop tasks at insertion time or already queued
These are all concerns that can be worked out but we should have them in mind when making decisions, especially because system complexity can sometimes make them difficult to implement.
Control the producer
Another possible solution to implement back-pressure is to control the producer. Instead of the producers knowing about the worker, the worker knows the producers and it can poll tasks at its own pace instead of receiving them in an uncontrolled manner.
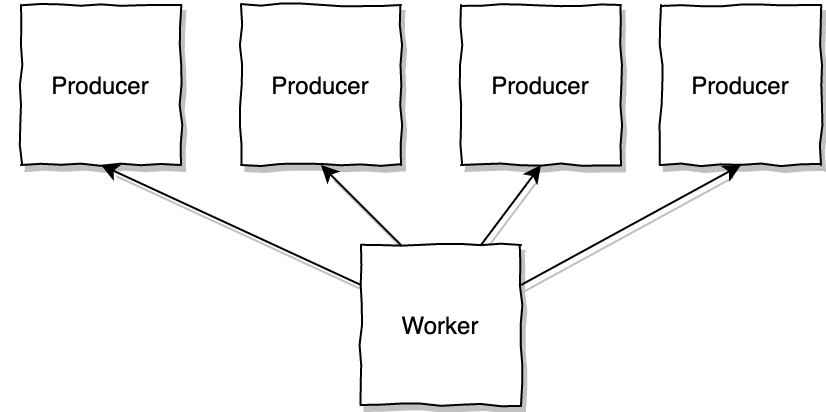
This kind of solution is interesting when we have a limited pool of producers that are in control of the data they produce, generating their own data or reading from disk for example, basically, when they can be considered the source of the data stream, otherwise we just move the problem upstream and we need to start considering a wider scale. Suppose we have a group of processes that receive http traffic faster than the downstream worker can poll them, what is happening to the requests that are not picked up right away? they need to go somewhere. On the edge there is always some buffer and in this case we have the TCP SYN and ACK queues (both bounded), but in the end we are back again to dropping and blocking (back-pressure).
Open vs Closed systems
When we are dealing with a closed system, where we control both producer and consumer behavior, if some part of the system becomes overloaded, requests will start to fail with errors or timeout, but we can define how producers will react, how many times will they retry before giving up, if we want them to retry right away or should they have some backoff policy. This is not that easy to accomplish, if not impossible at all, when we are dealing with an open system where our input originates from an unknown number of producers that we cannot control or trust. In this case, it is not feasible to make them slowdown.
This is where a circuit-breaker could help, it works like the bouncer at the disco’s door, letting people in or sending them away. This component is a proxy that seats in front of our system and decides if a given request goes through or not, based in a set of tracked system metrics: failures, queue sizes, timeouts and similar. When any of this metrics is considered above a defined threshold it returns an error back to the client and prevents further computation, shielding the downstream components from further impact.
In the end
When preparing for unexpected load it is easy to get lost in the multitude of possibilities and issues that need to be considered, however inaction will eventually lead to failure. When trying to improve system resiliency it becomes interesting to analyse, test, measure and reason, figuring out which approach works best for each specific component, taking into consideration complexity, requirements, infrastructure, cost limitations, etc.